Beginner
What's Google BigQuery¶
BigQuery is a data warehouse designed for storing and querying large datasets. It's optimized for querying and analyzing data, but not for inserting/deleting/modifying data.
SQL¶
SQL (Structured Query Language) is a standard language for accessing and manipulating databases. SQL has numerous flavors (e.g. MySql, Microsoft SQL Server, PostgreSQL), all of which follow similar patterns and syntax, but each flavor has its own quirks and way of doing things.
BigQuery has its own flavor of SQL. Therefore, if you want to know how to create tables, aggregate data, calculate rolling averages, ... with BigQuery, you need to find the correct BigQuery SQL syntax. A Google search such as "How to select a random row from a table in SQL" will often lead you astray, as the results will not be specific to BigQuery.
As always, a good place to answer your "how do I do this thing?" questions is to refer to the official BigQuery docs.
Hello World¶
Here's a look at the BigQuery console in its simplest form.
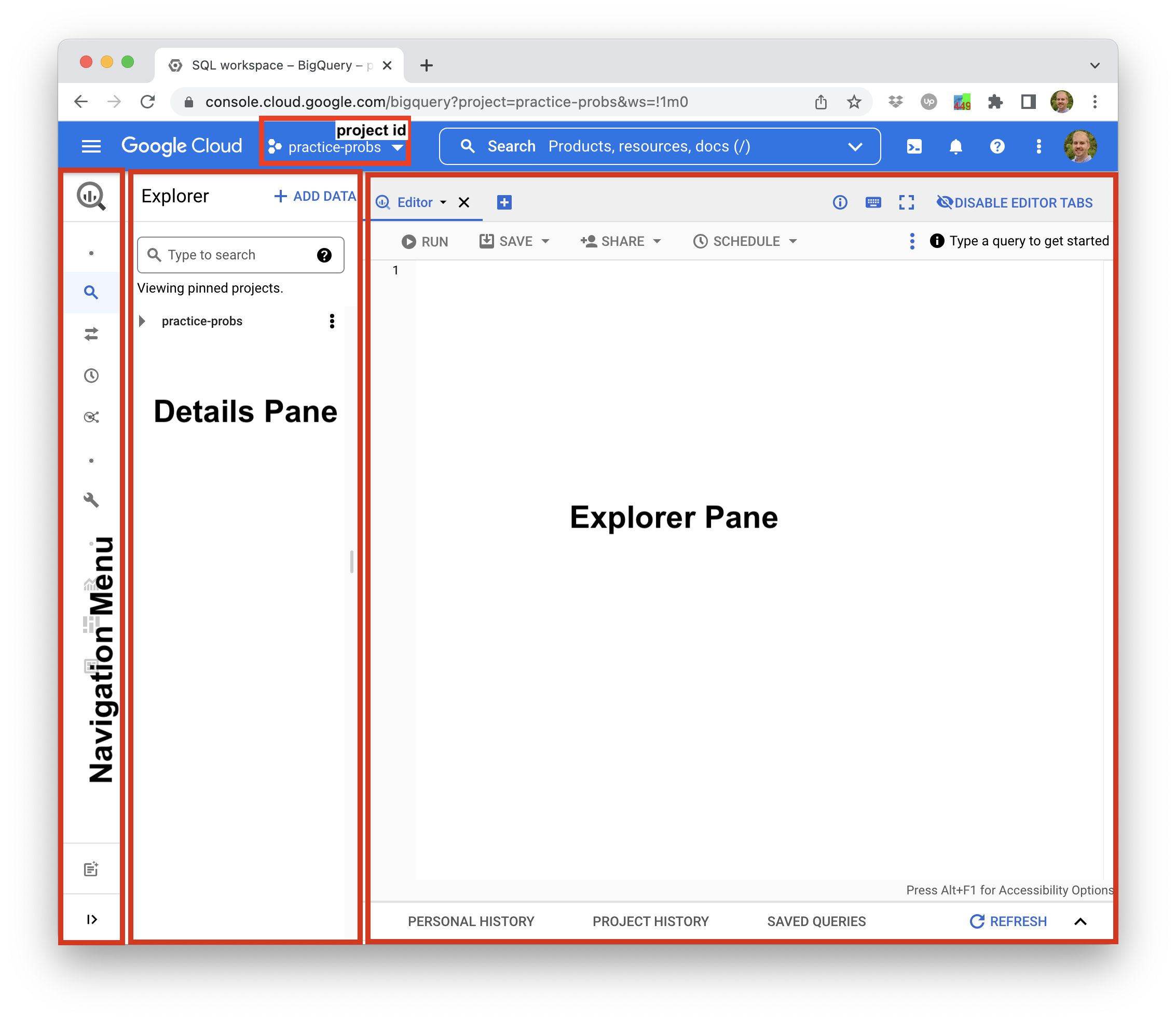
Notice the project id in the header. Our project id is practice-probs. Yours will be different.
Projects > Datasets > Tables¶
In BigQuery, tables live within datasets and datasets live within projects.
- abc-grocery <- project
- primary <- dataset
- sales <- table
- customers
- products
- social
- twitter_posts
- instagram_posts
- facebook_posts
Make a dataset¶
Before we make our first table, we'll need to make a dataset. The easiest way to make a dataset is to use the web interface like this.
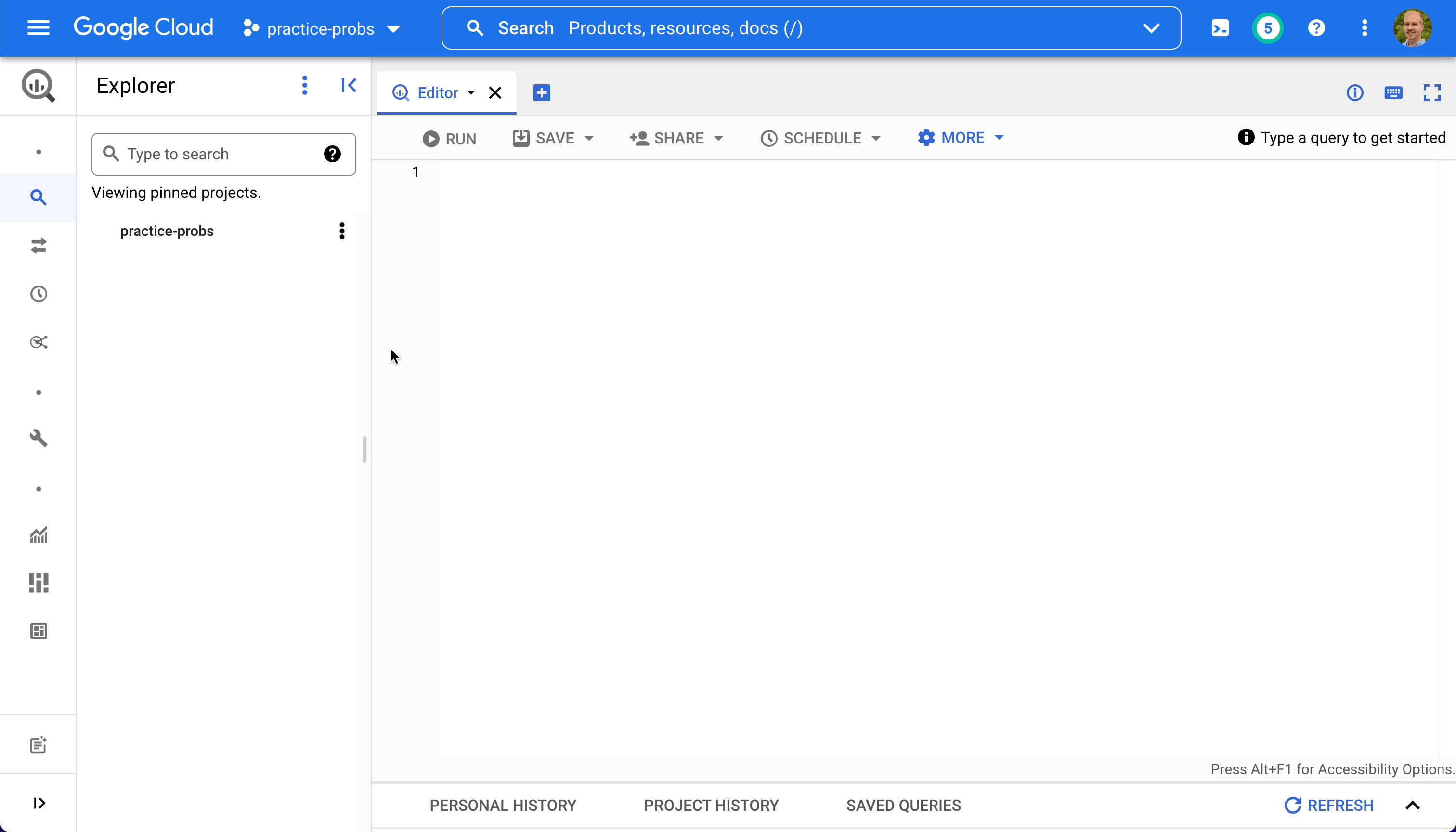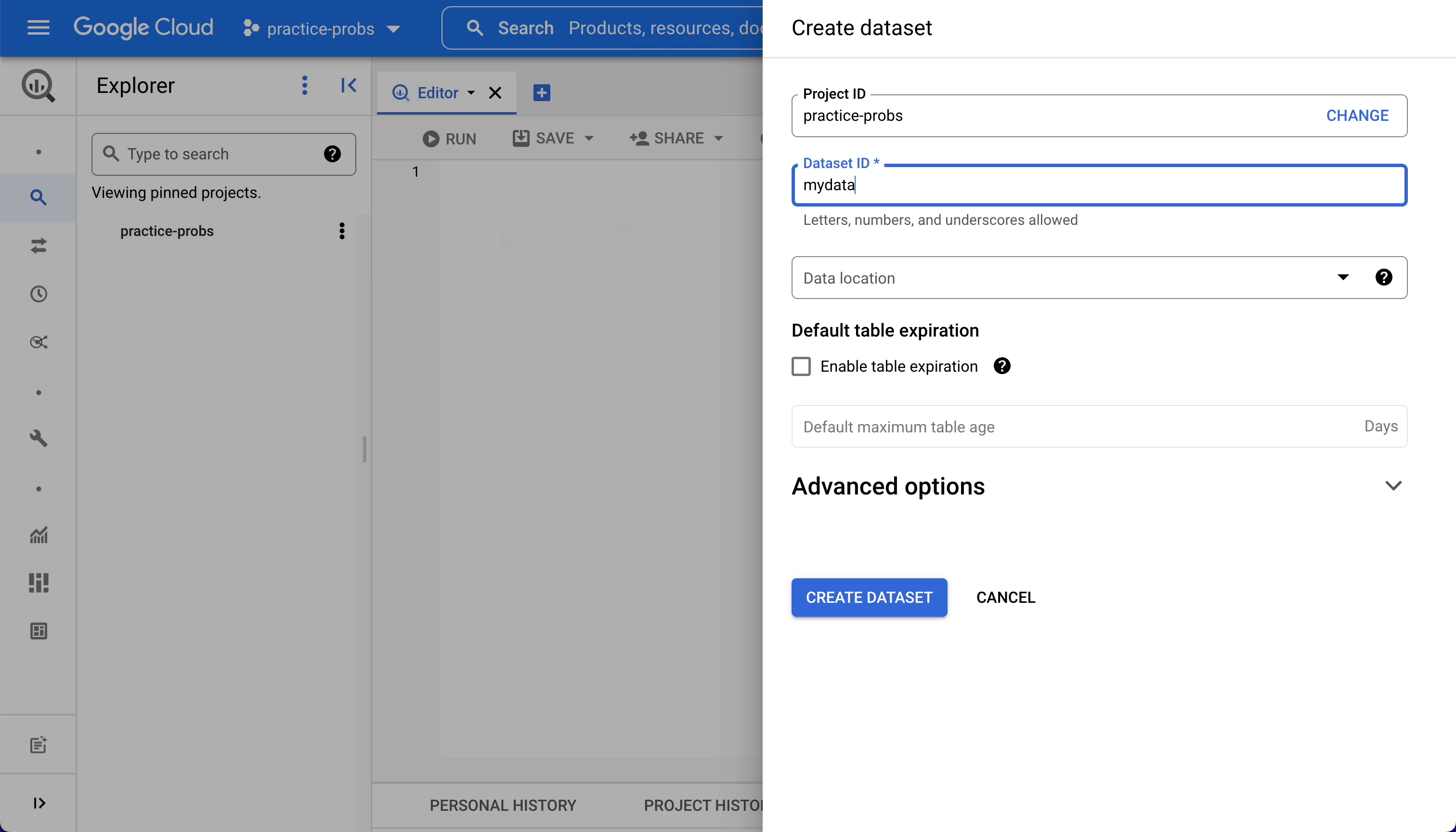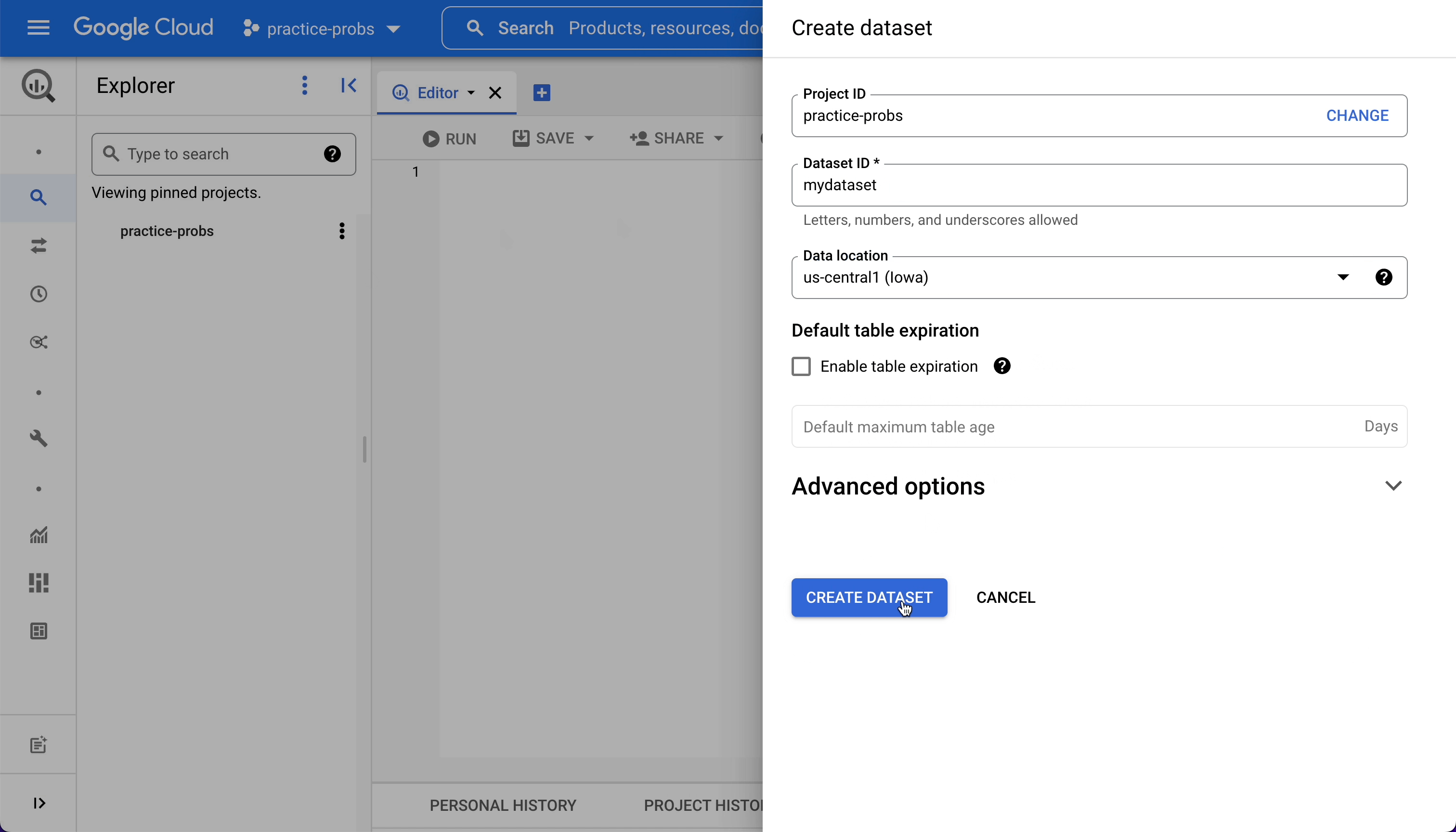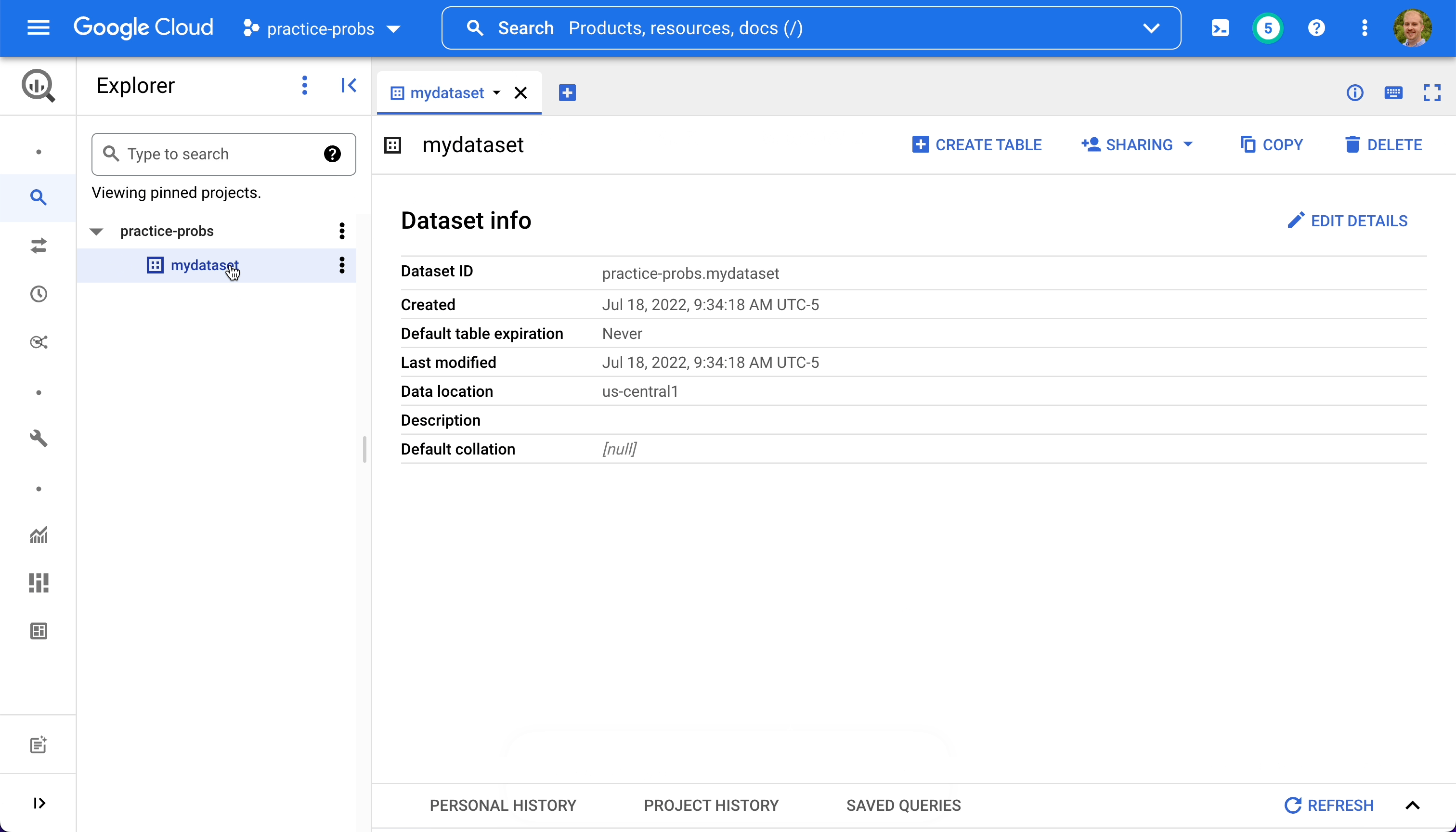
- Click the three dots next to your project-id in the explorer pane.
- Click Create dataset.
- Set Dataset ID equal to "mydataset" and then choose a Data location close to you.
- Click Create Dataset.
There are lots of other ways to make a dataset. For example, we could make the same dataset using a SQL query like this.
CREATE SCHEMA project-id.mydataset
Make a table¶
Now we can make a table within mydataset by executing the following SQL statement in the editor.
CREATE TABLE mydataset.helloworld AS
SELECT 1 AS id, 'John' AS name UNION ALL
SELECT 2 AS id, 'Ryan' AS name UNION ALL
SELECT 3 AS id, 'Carly' AS name UNION ALL
SELECT 4 AS id, 'Kora' AS name;
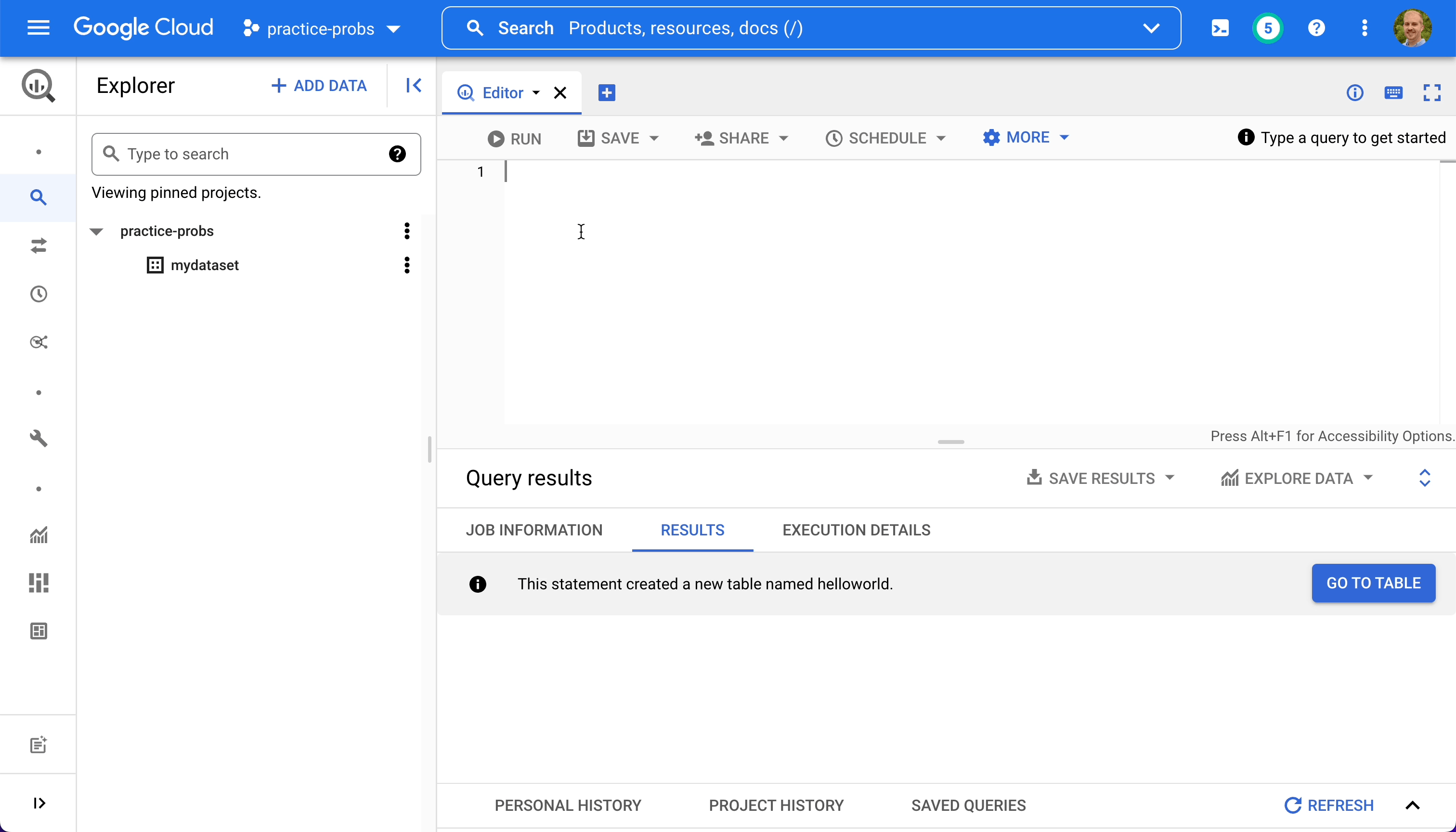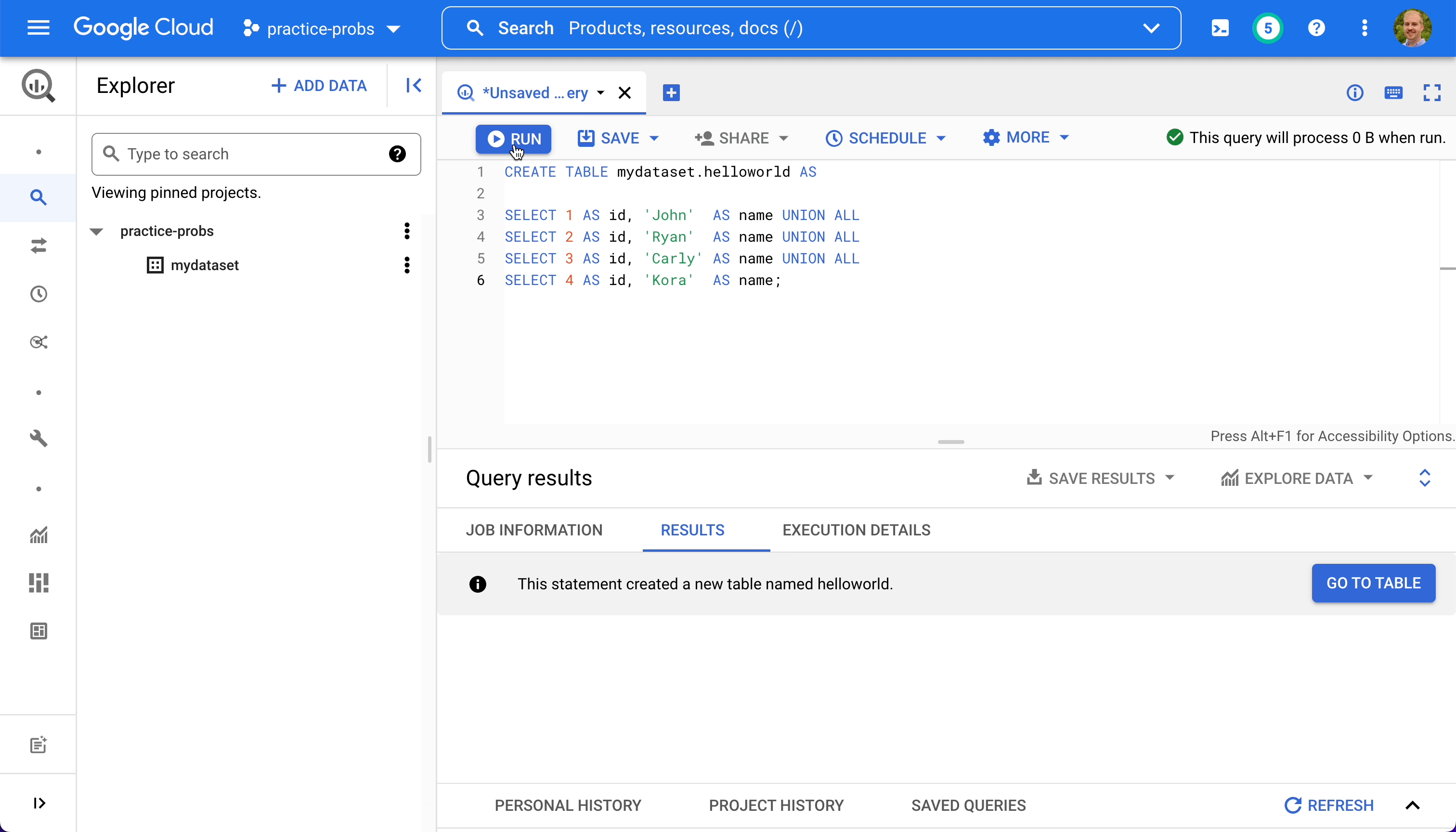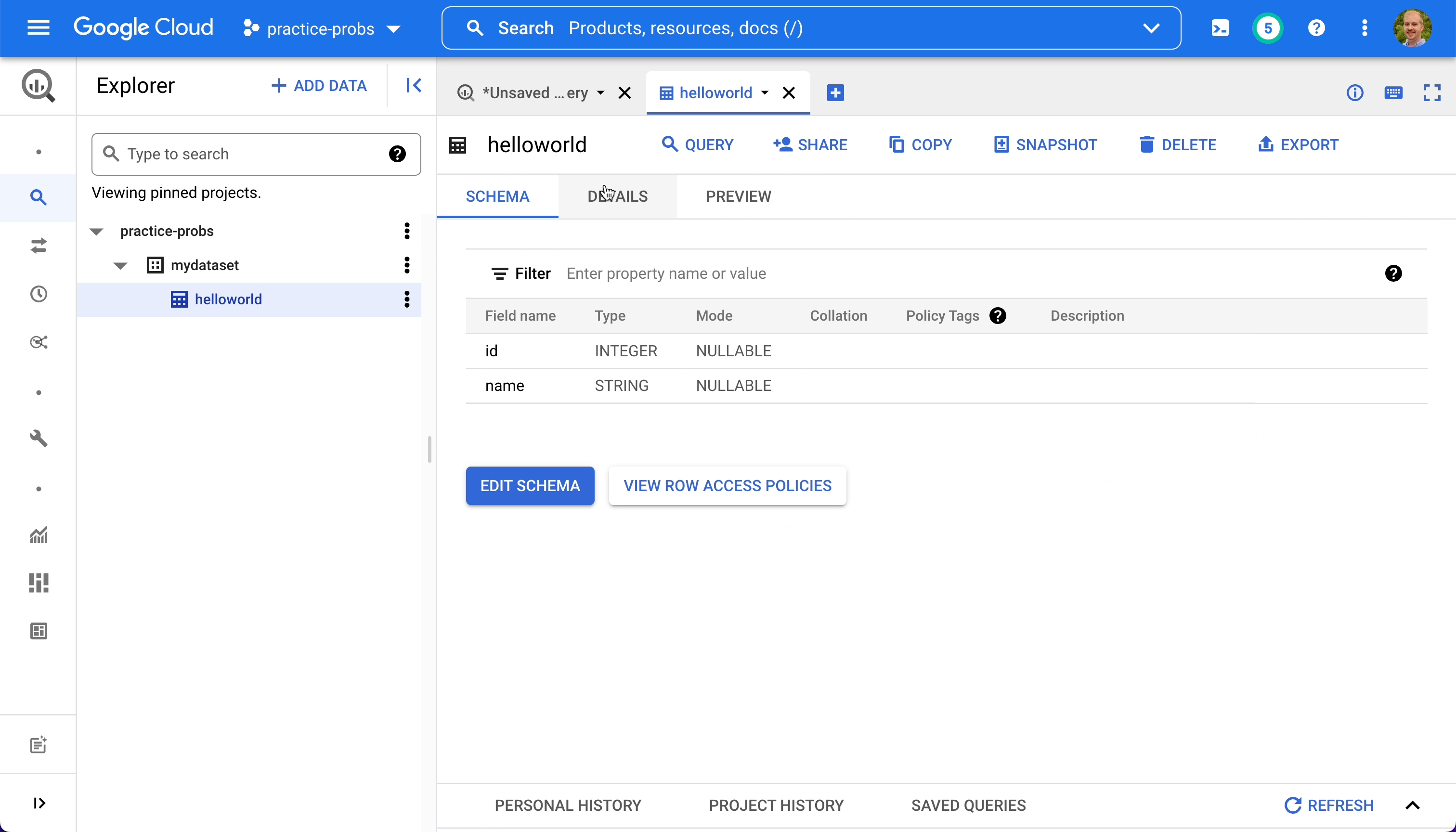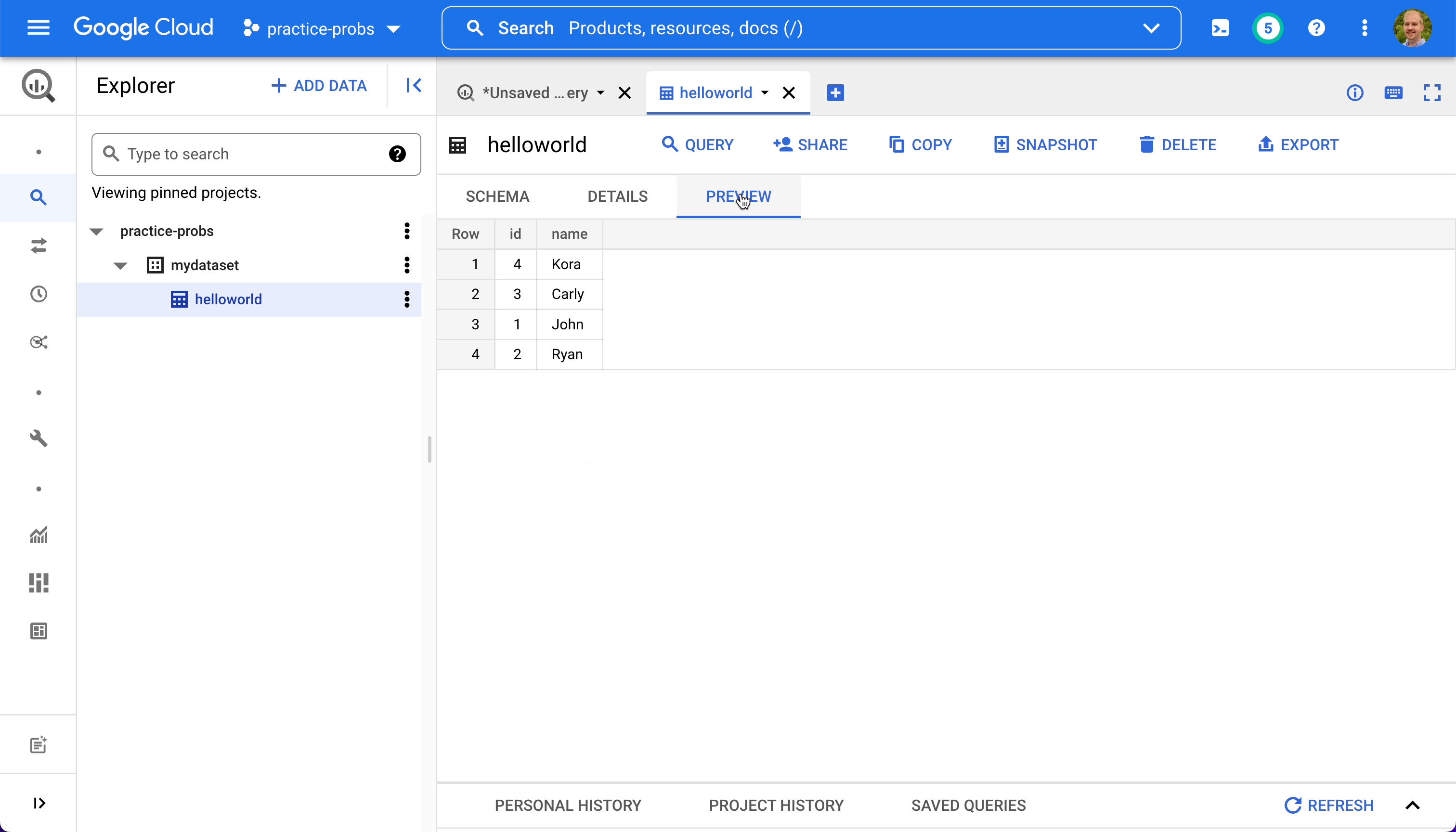
We can inspect the table's schema and details, and preview its data.
...
Query a table¶
Now let's query the table we just created by executing the following SQL statement.
SELECT * FROM mydataset.helloworld WHERE name IN ('Carly', 'Ryan');
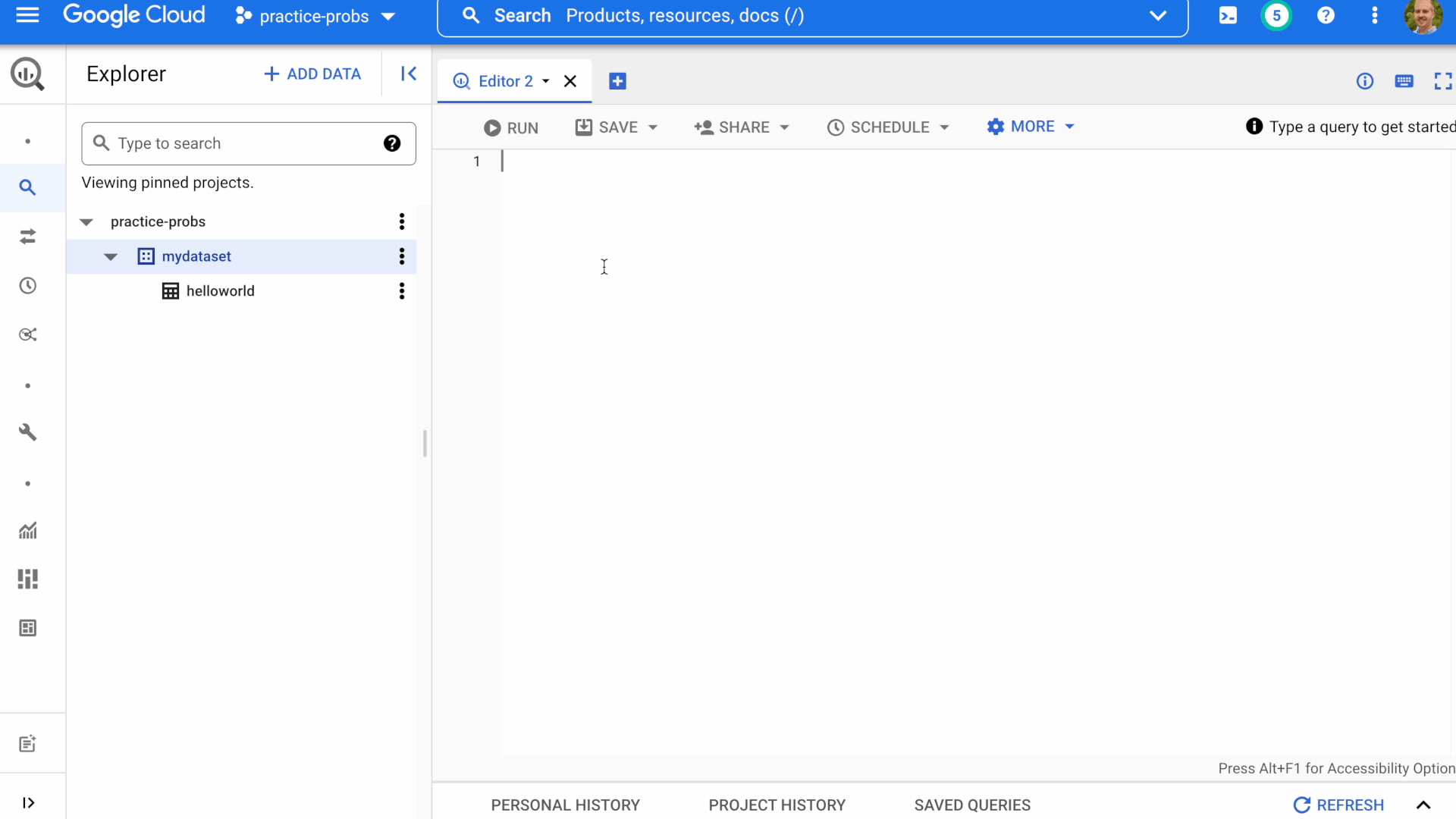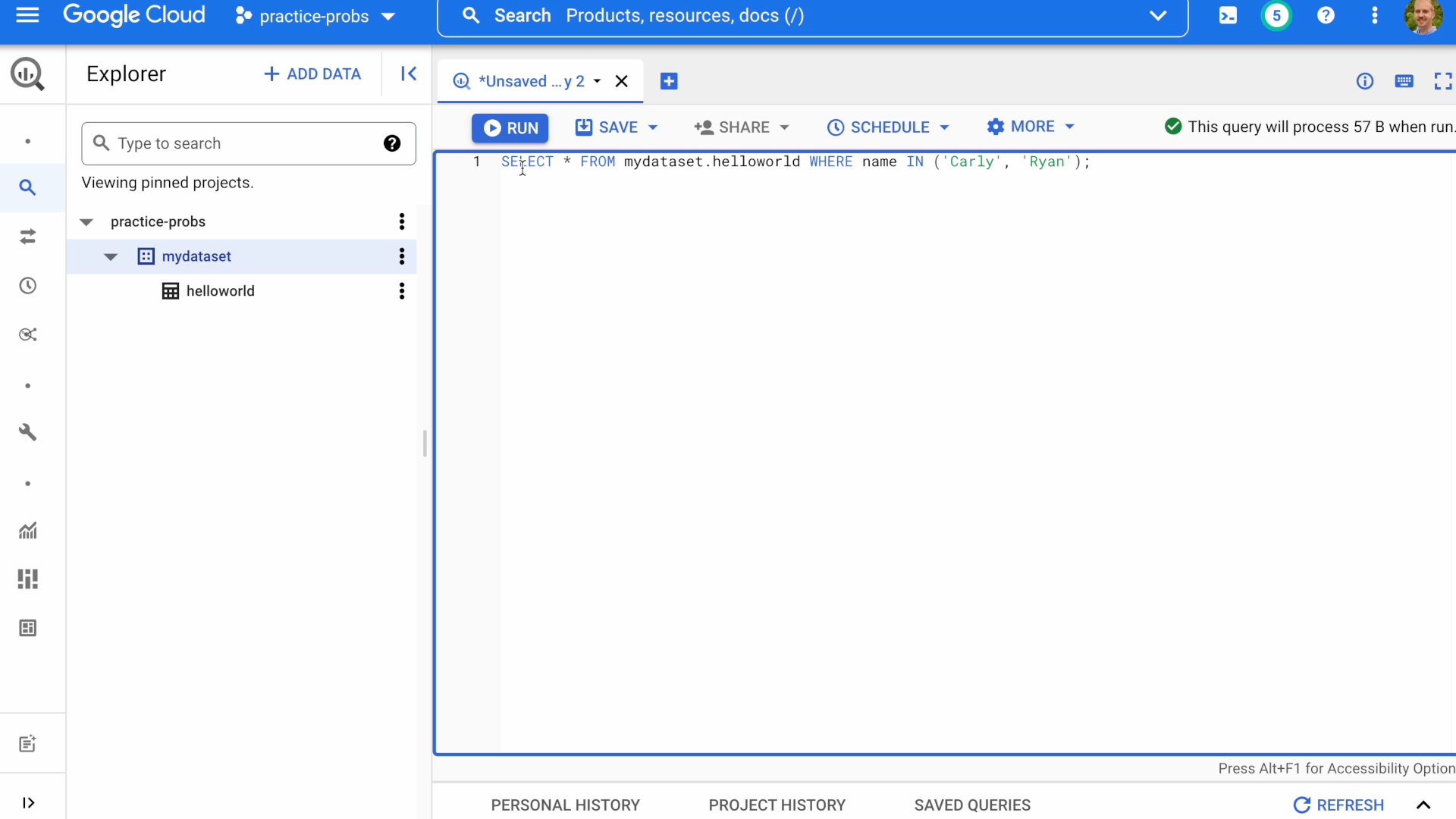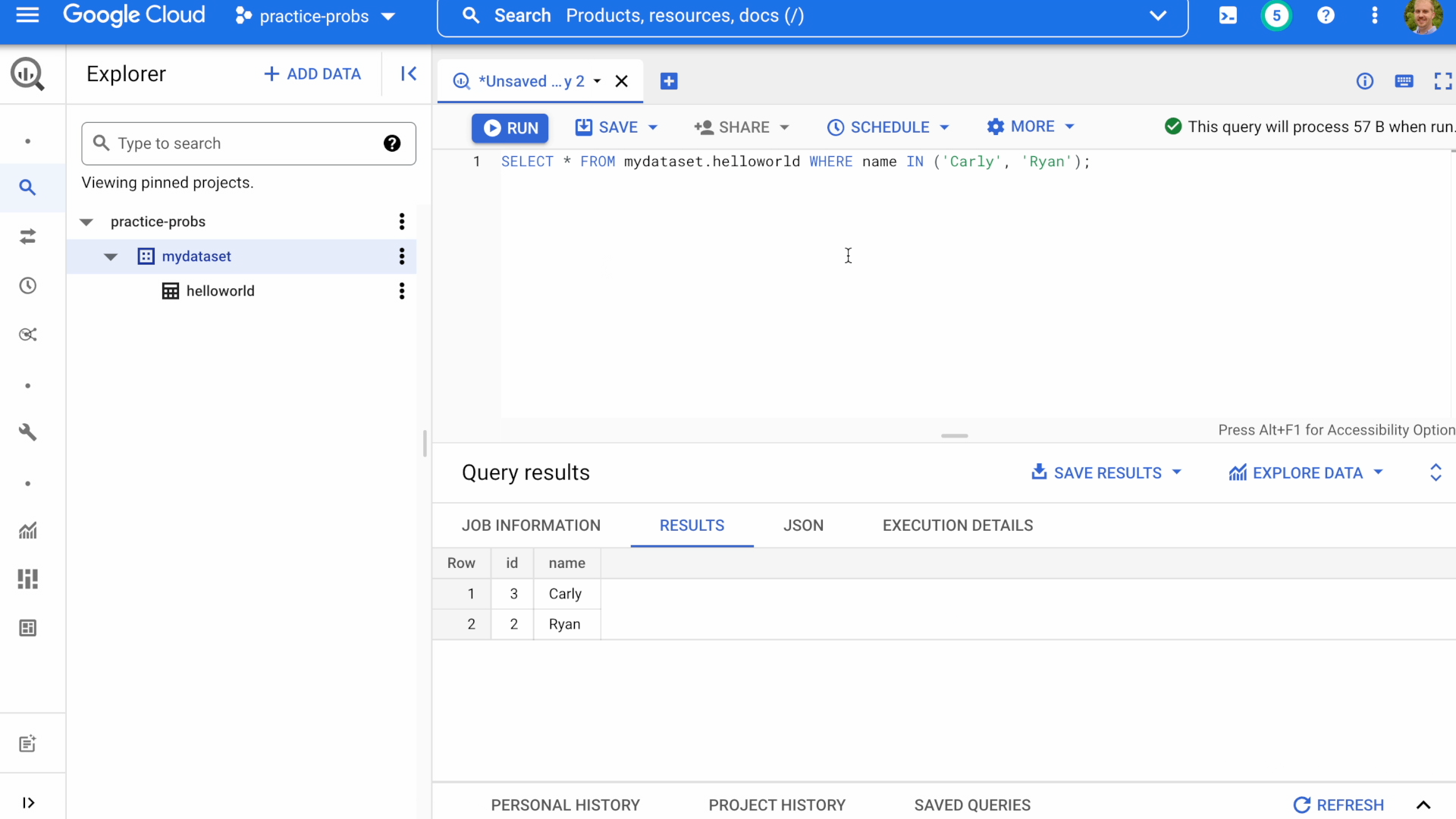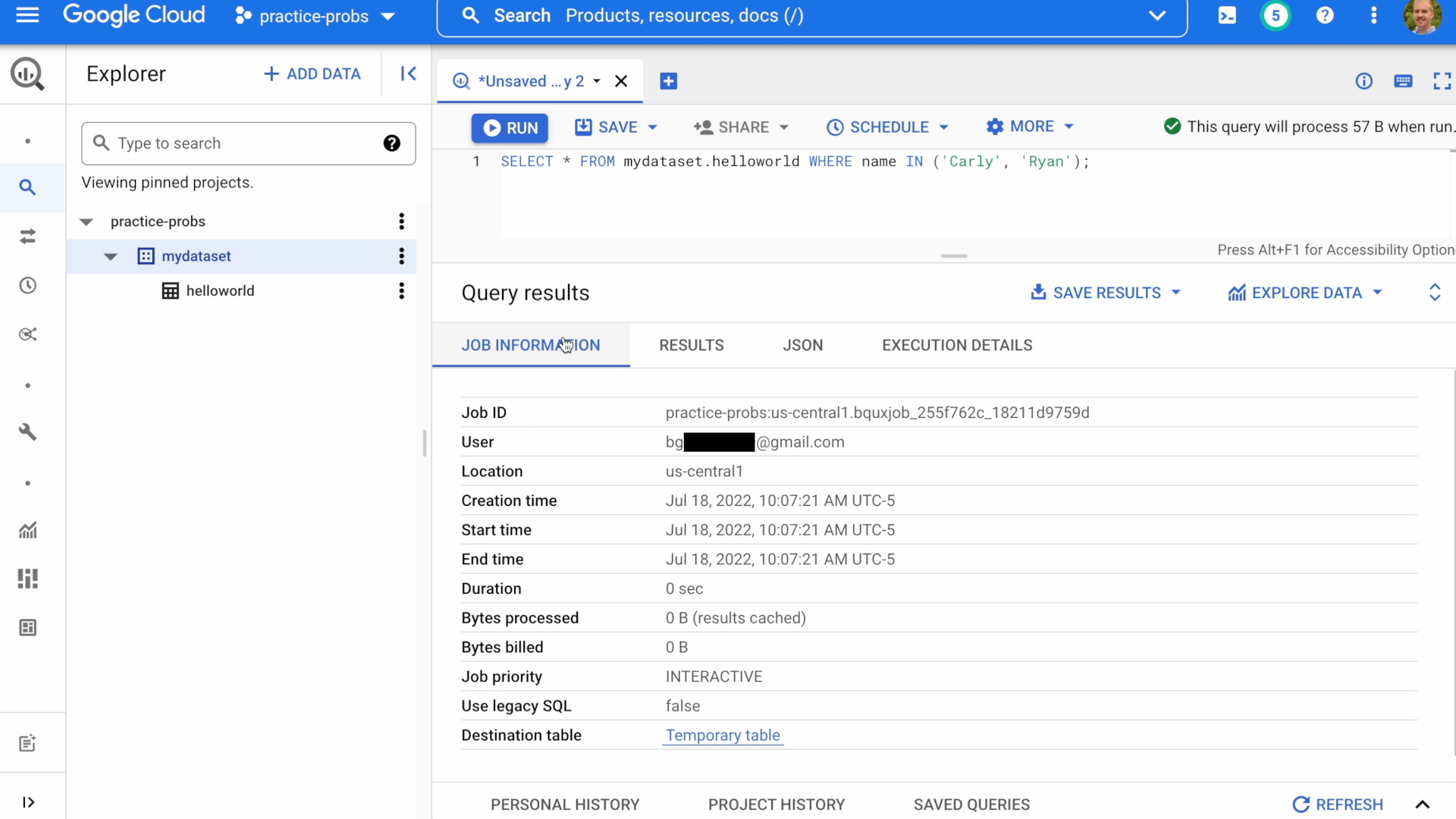
Important
Notice the estimate query "cost" reported as bytes processed in the top right of the details pane.
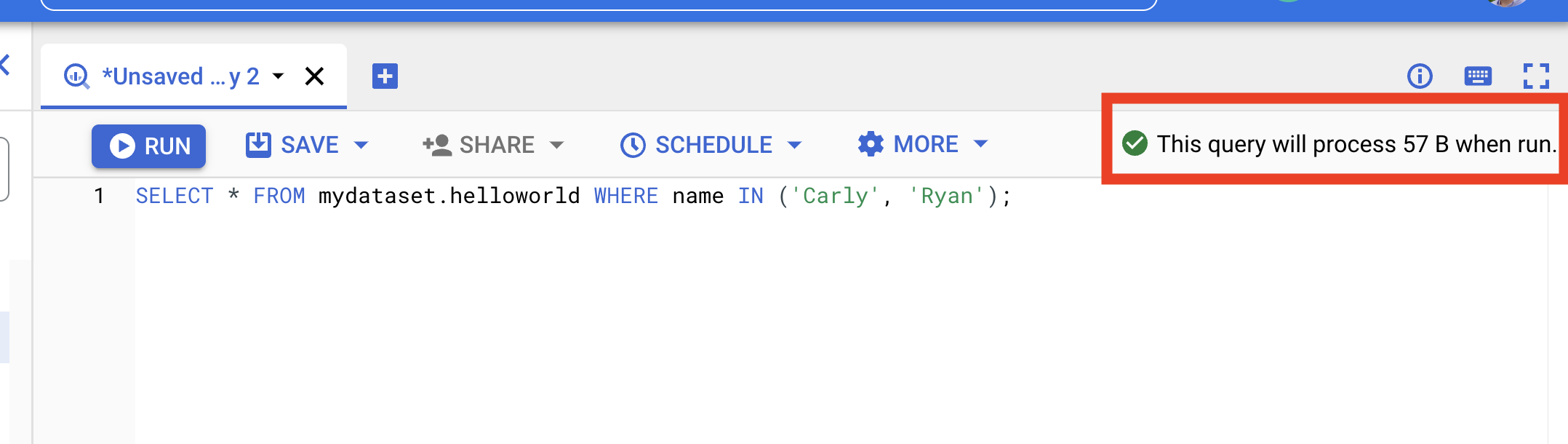
In this example, BigQuery expects the query to process 57 bytes. For reference, 1TB of data processed currently costs $5 (although the first TB per month is free.)
BigQuery Jobs¶
In BigQuery, each executed query translates into a BigQuery job with details like Who ran the query? When was the query executed? and How many bytes of data did the query process?
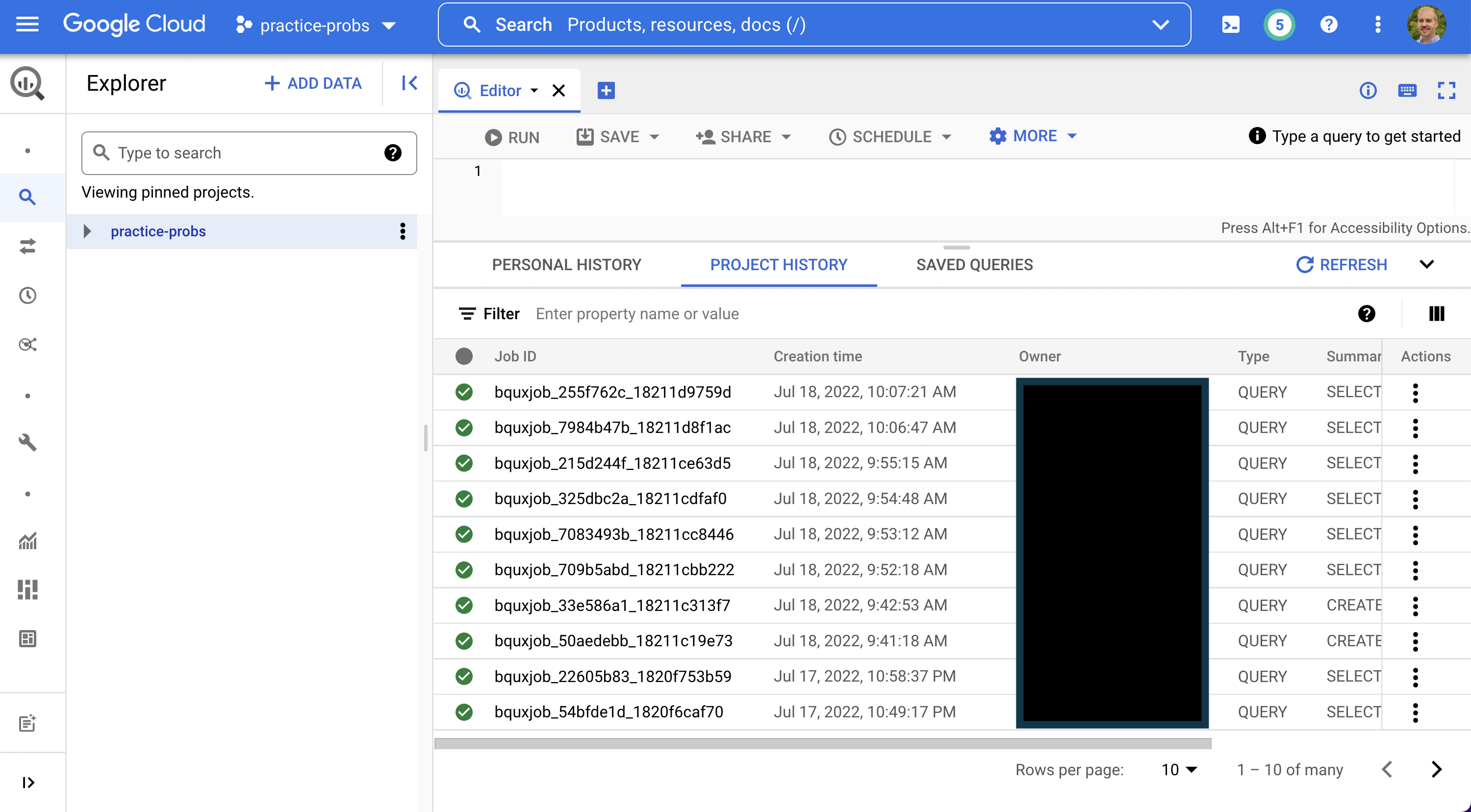
Jobs are conveniently stored under the Project History and Personal History tabs, so you can fetch previously run queries even if you didn't explicitly save them!
Query Notes¶
- BigQuery SQL is case-insensitive (but most people use all caps by convention)
- Tables need to be qualified with their parent dataset name (e.g.
foo.baras opposed to simplybar). Often, you'll see tables qualified by their parent project and dataset (e.g.myproject.foo.bar).
Tips & Tricks¶
-
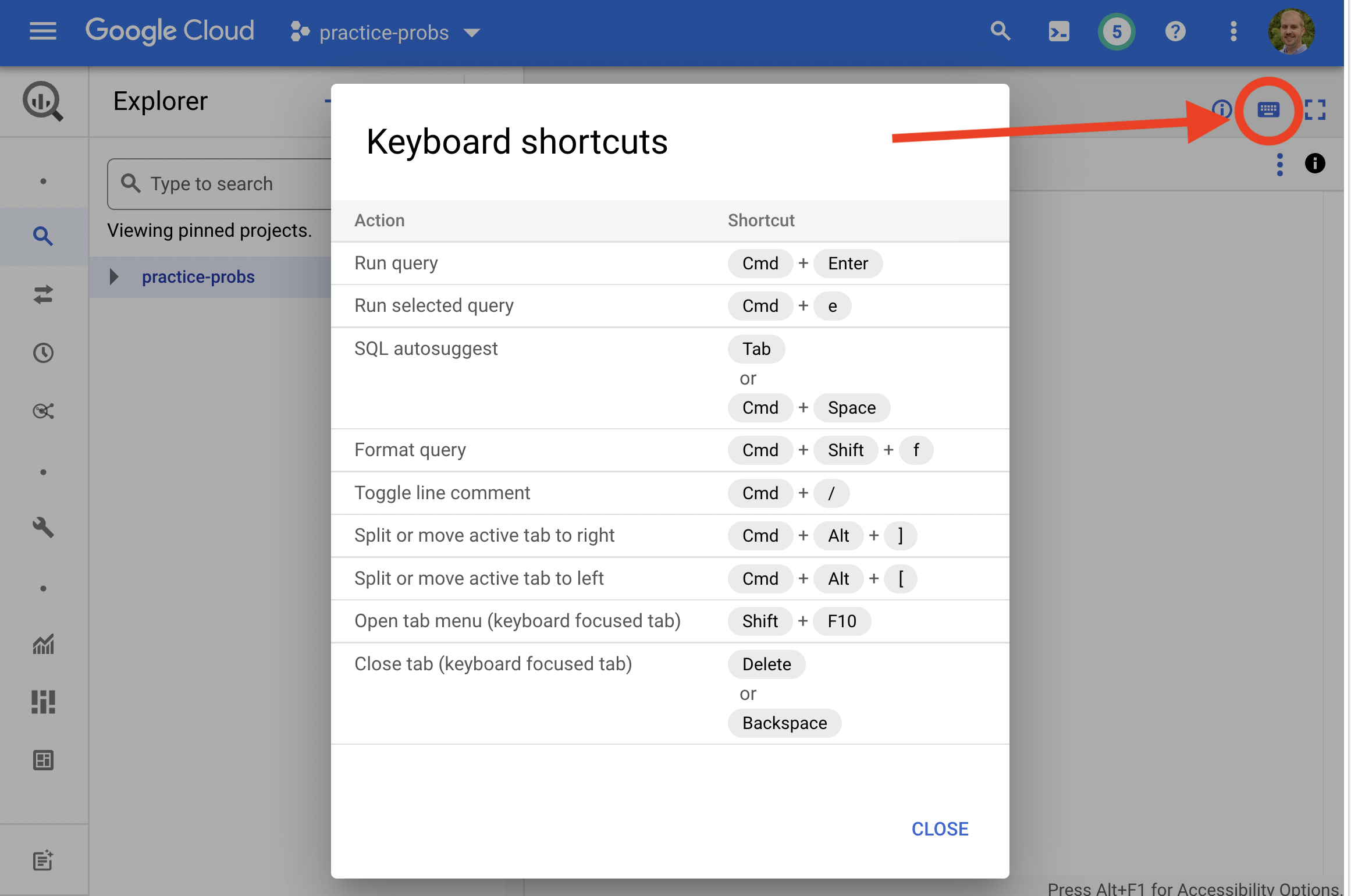
You can view a list of keyboard shortcuts by clicking on the keyboard icon near the top right of the details pane.
-
If you have multiple query statements in the editor, you can run one of them by highlighting it clicking Run (or use the shortcut
cmd + return(mac),ctrl + enter(windows)).
Public Datasets¶
BigQuery hosts some really cool public datasets that we'll make use of throughout this problem set. To access the public datasets,
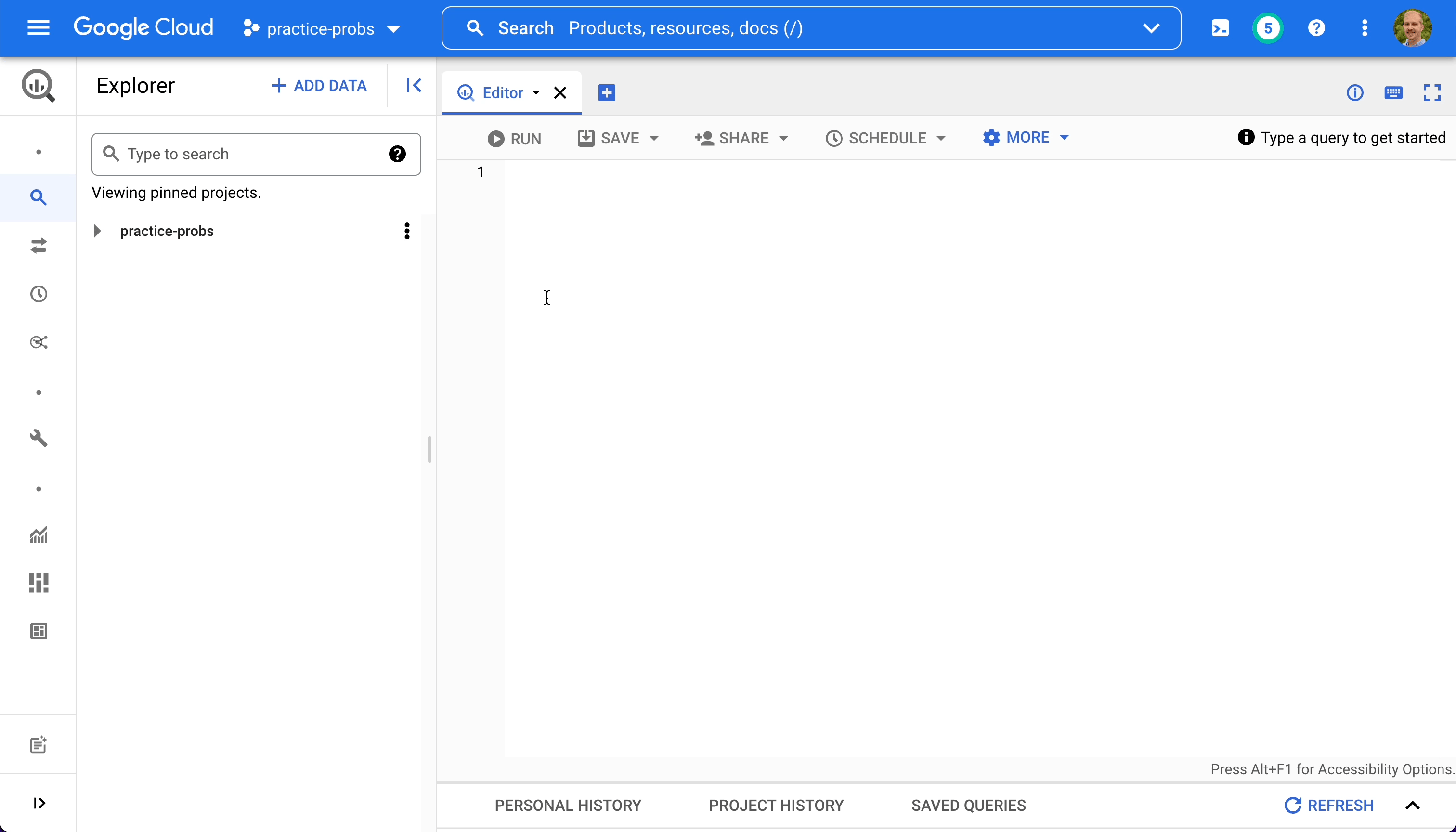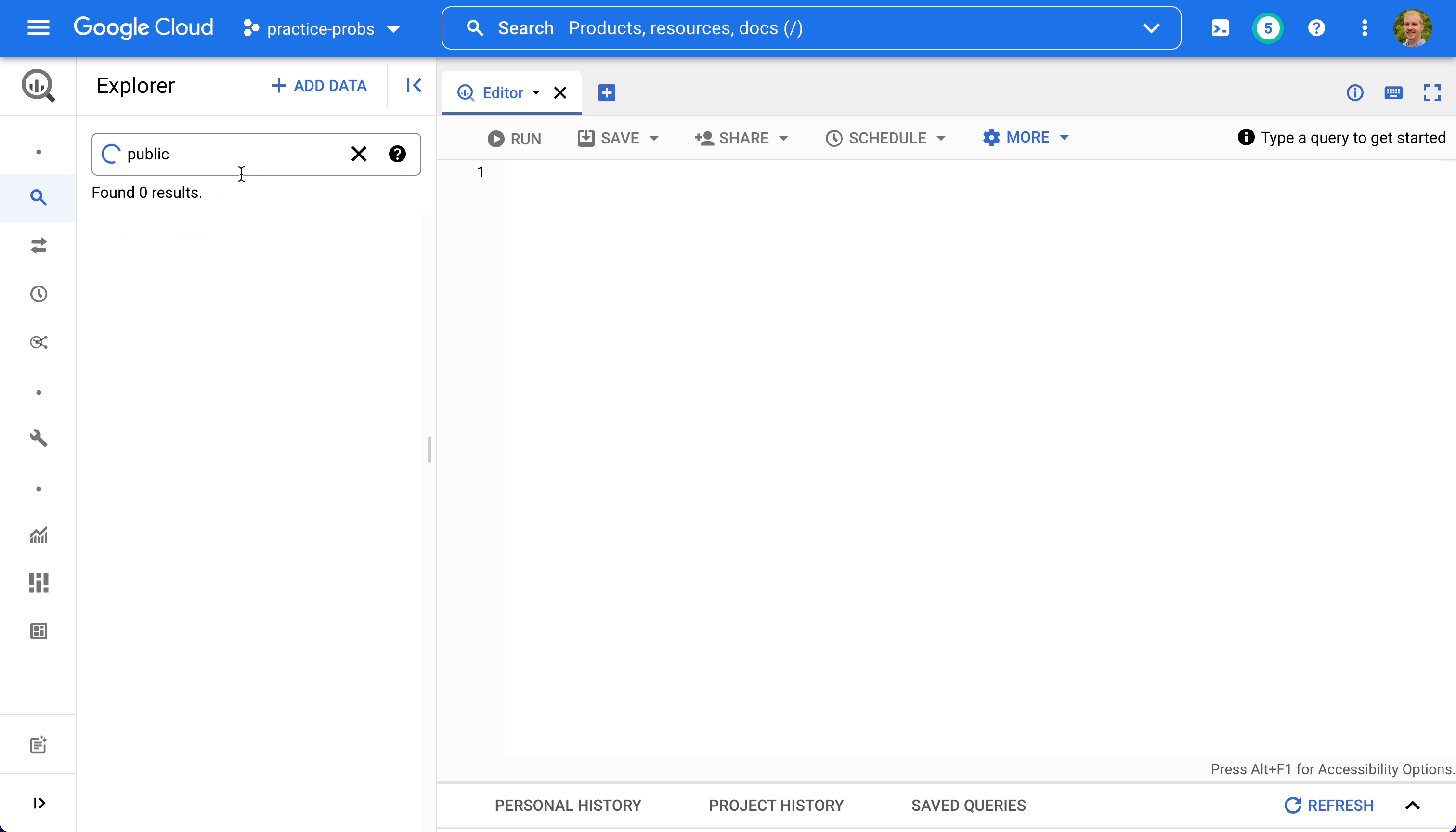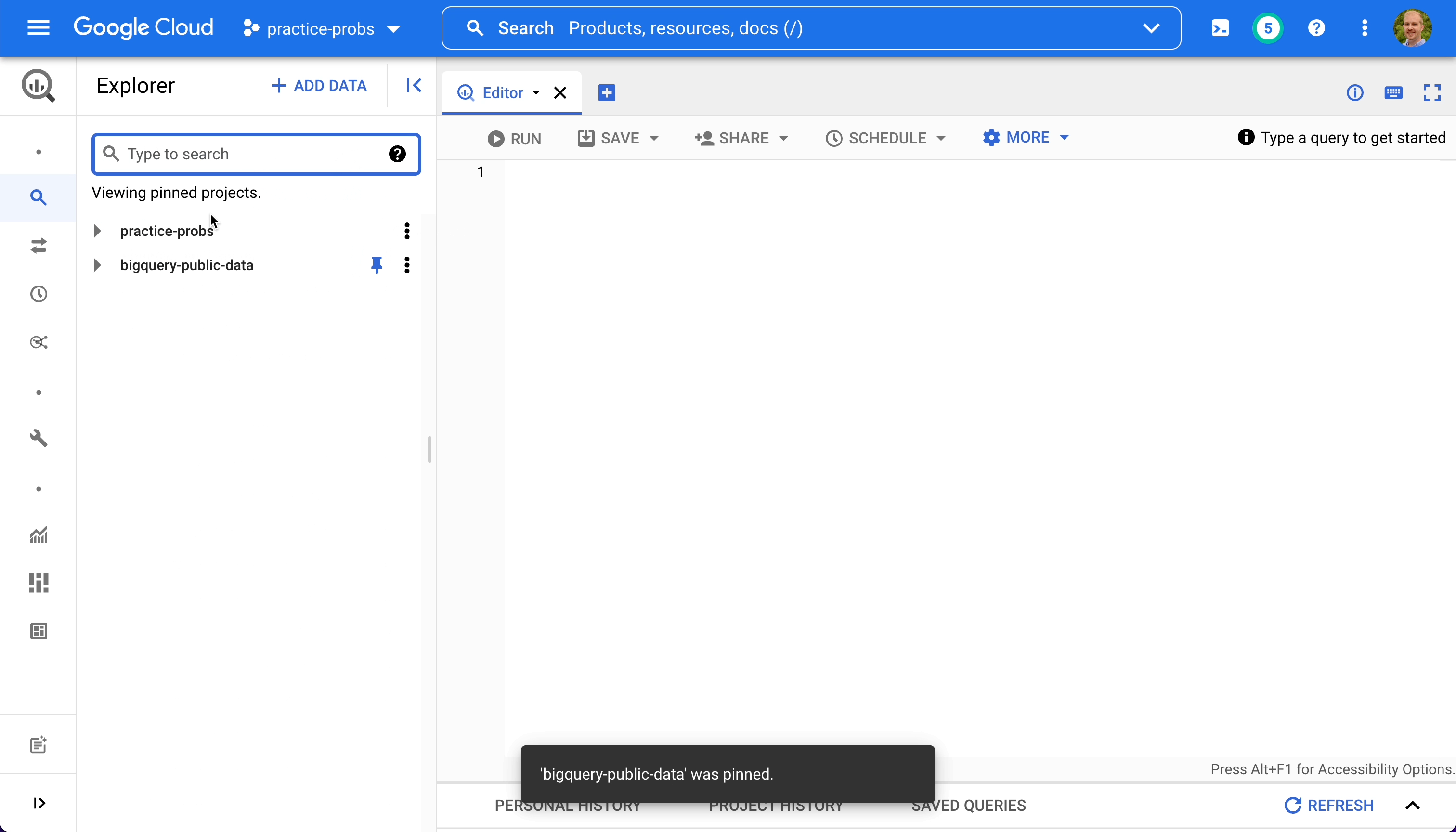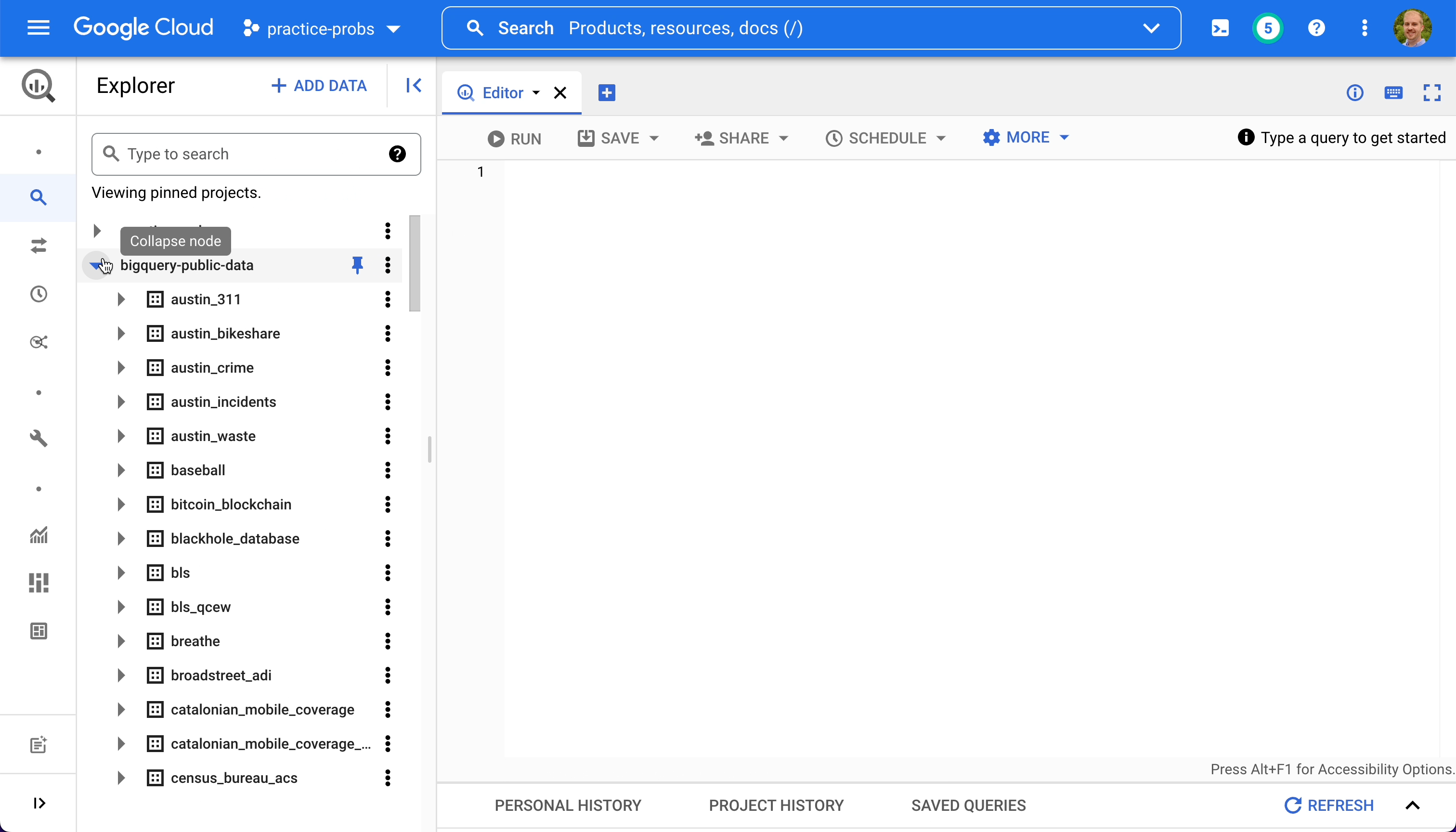
- Search for "public" in the explorer pane
- Click "Broaden search to all projects"
- Find the project titled "bigquery-public-data" and pin it
- Clear the text inside the search bar
- Expand the bigquery-public-data project to see dozens of datasets within it.
You can query any of these datasets, but be cautious as some of them are pretty large (and thus expensive  ).
).
Example
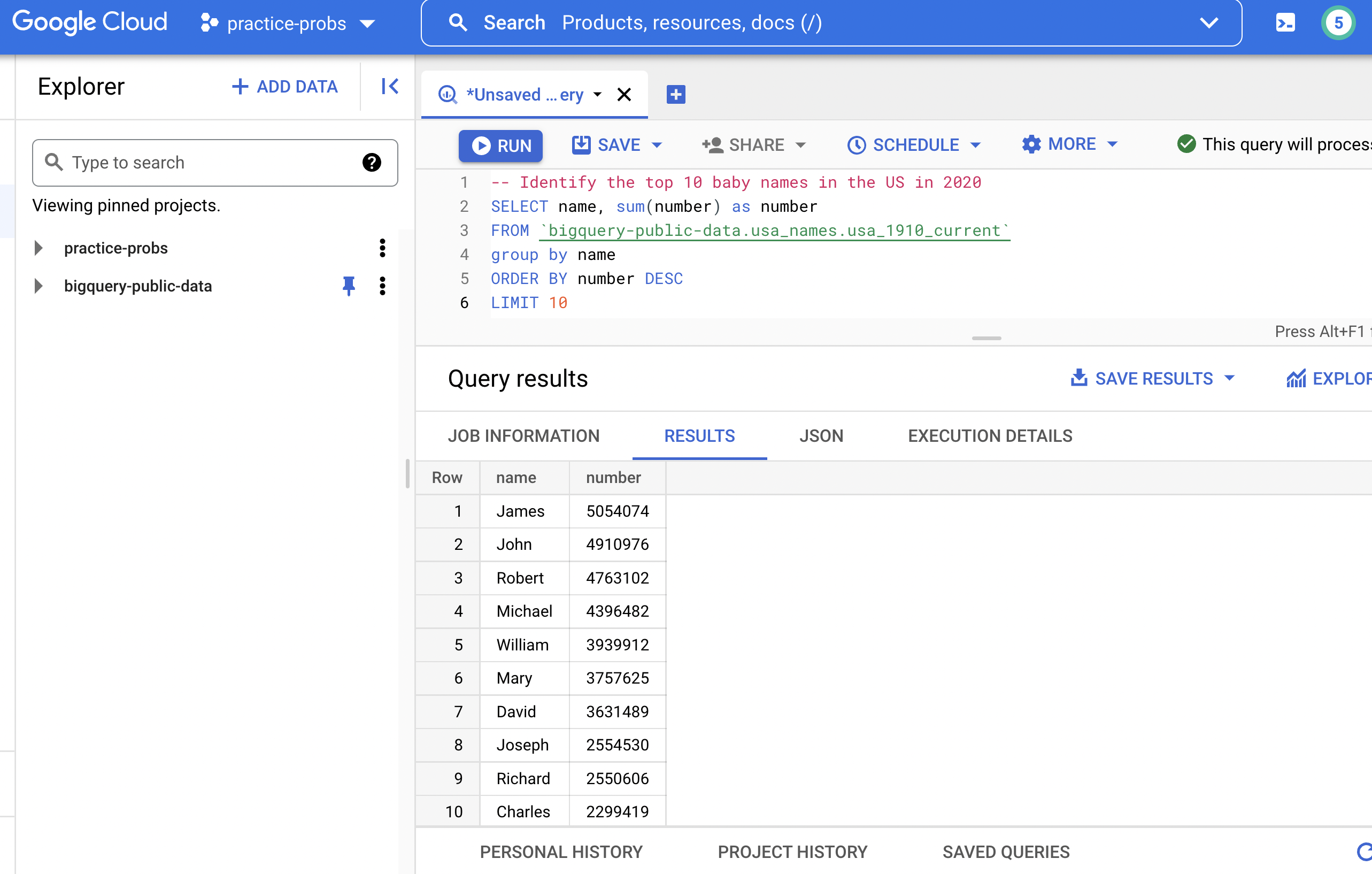
-- Identify the top 10 baby names in the US in 2020
SELECT name, sum(number) as number
FROM `bigquery-public-data.usa_names.usa_1910_current`
group by name
ORDER BY number DESC
LIMIT 10