Humans Problem¶
You've developed a  machine learning model that classifies images. Specifically, it outputs labels with
non-negligible probabilities.
machine learning model that classifies images. Specifically, it outputs labels with
non-negligible probabilities.
import pandas as pd
predictions = pd.DataFrame.from_dict({
'preds': {
12: "{'dog': 0.55, 'cat': 0.25, 'squirrel': 0.2}",
41: "{'telephone pole': 0.8, 'tower': 0.1, 'stick': 0.1}",
43: "{'man': 0.65, 'woman': 0.33, 'monkey': 0.02}",
46: "{'waiter': 0.45, 'waitress': 0.30, 'newspaper': 0.15, 'cat': 0.10}",
49: "{'nurse': 0.50, 'doctor': 0.50}",
72: "{'baseball': 0.8, 'basketball': 0.15, 'football': 0.05}",
91: "{'woman': 0.62, 'man': 0.28, 'elephant': 0.10}"
}
})
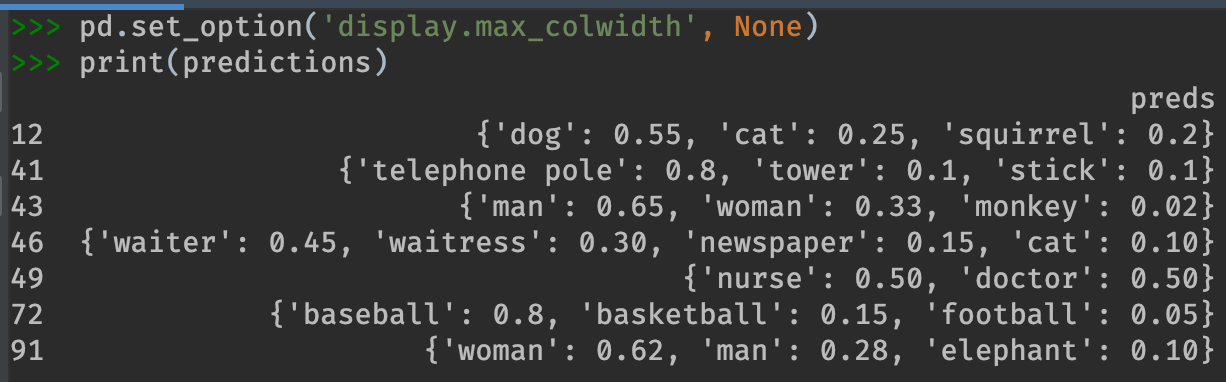
print(predictions)
# preds
# 12 {'dog': 0.55, 'cat': 0.25, 'squirrel': 0.2}
# 41 {'telephone pole': 0.8, 'tower': 0.1, 'stick': 0.1}
# 43 {'man': 0.65, 'woman': 0.33, 'monkey': 0.02}
# 46 {'waiter': 0.45, 'waitress': 0.30, 'newspaper': 0.15, 'cat': 0.10}
# 49 {'nurse': 0.50, 'doctor': 0.50}
# 72 {'baseball': 0.8, 'basketball': 0.15, 'football': 0.05}
# 91 {'woman': 0.62, 'man': 0.28, 'elephant': 0.10}
Each row in predictions represents predictions for a different image.
Insert a column called prob_human that calculates the probability each image represents a human. You can use the
following list of strings to identify human labels.
humans = ['doctor', 'man', 'nurse', 'teacher', 'waiter', 'waitress', 'woman']
Prevent pandas from truncating print(predictions)
When you print(predictions), the output might get truncated like this.
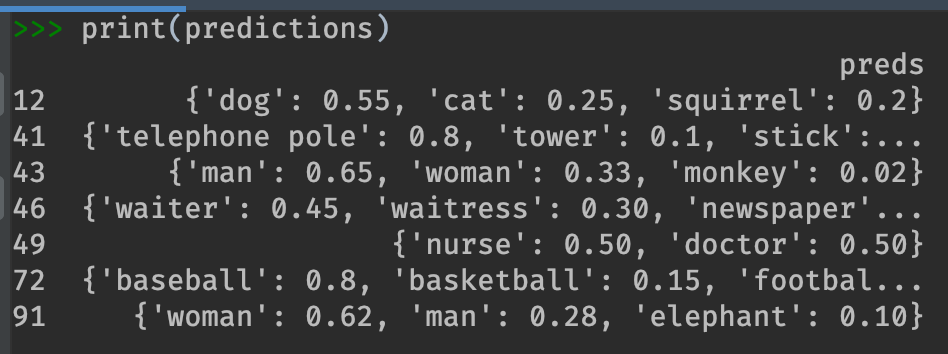
To prevent this, set display.max_colwidth to None.
pd.set_option('display.max_colwidth', None)
print(predictions)