Making Headlines Solution¶
from selenium import webdriver
from selenium.webdriver.common.by import By
# Instantiate a WebDriver
driver = webdriver.Chrome()
driver.get("https://seleniumplayground.practiceprobs.com/")
# Fetch the title
title = driver.find_element(By.ID, "selenium-playground")
html = title.get_attribute("innerHTML")
# Close the WebDriver
driver.close()
# Extract the relevant text
title_str = html.split("<")[0]
print(title_str)
# Selenium Playground
Explanation¶
We begin by identifying the HTML element we want to access using the Inspect tool.
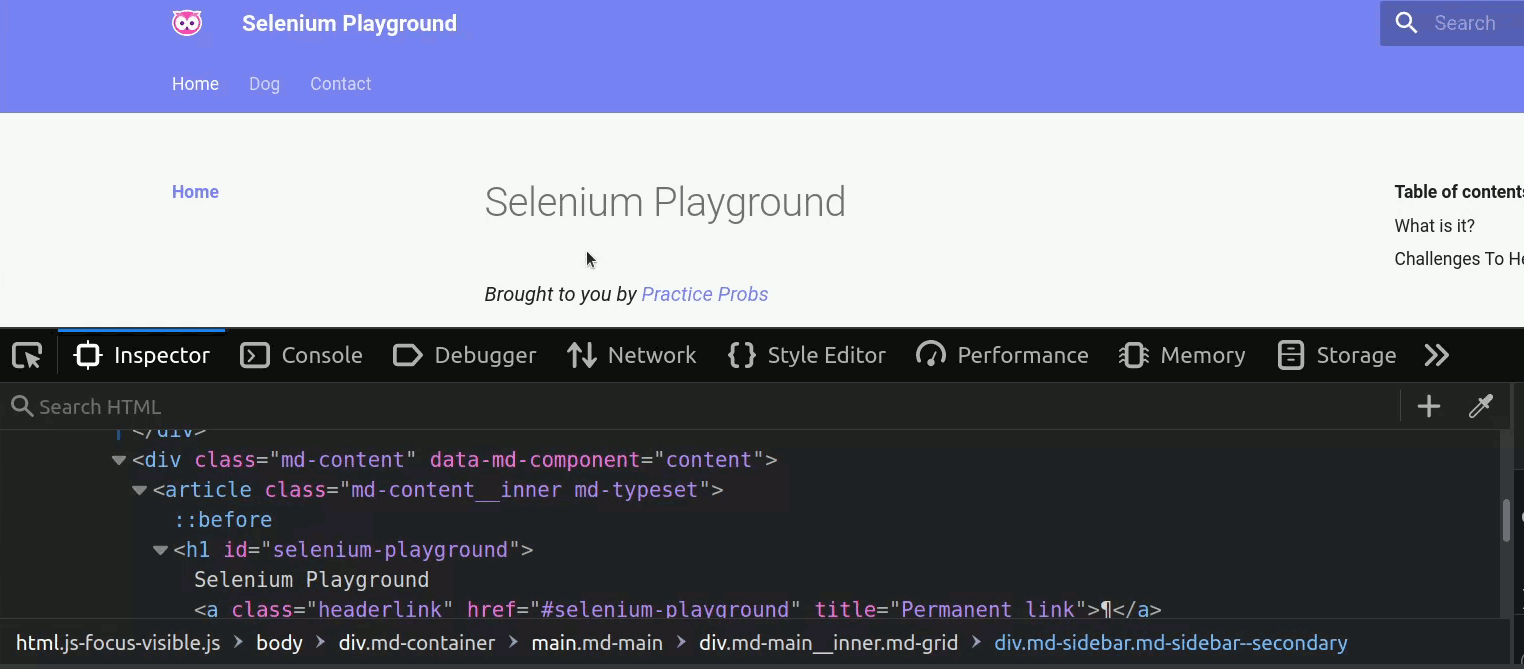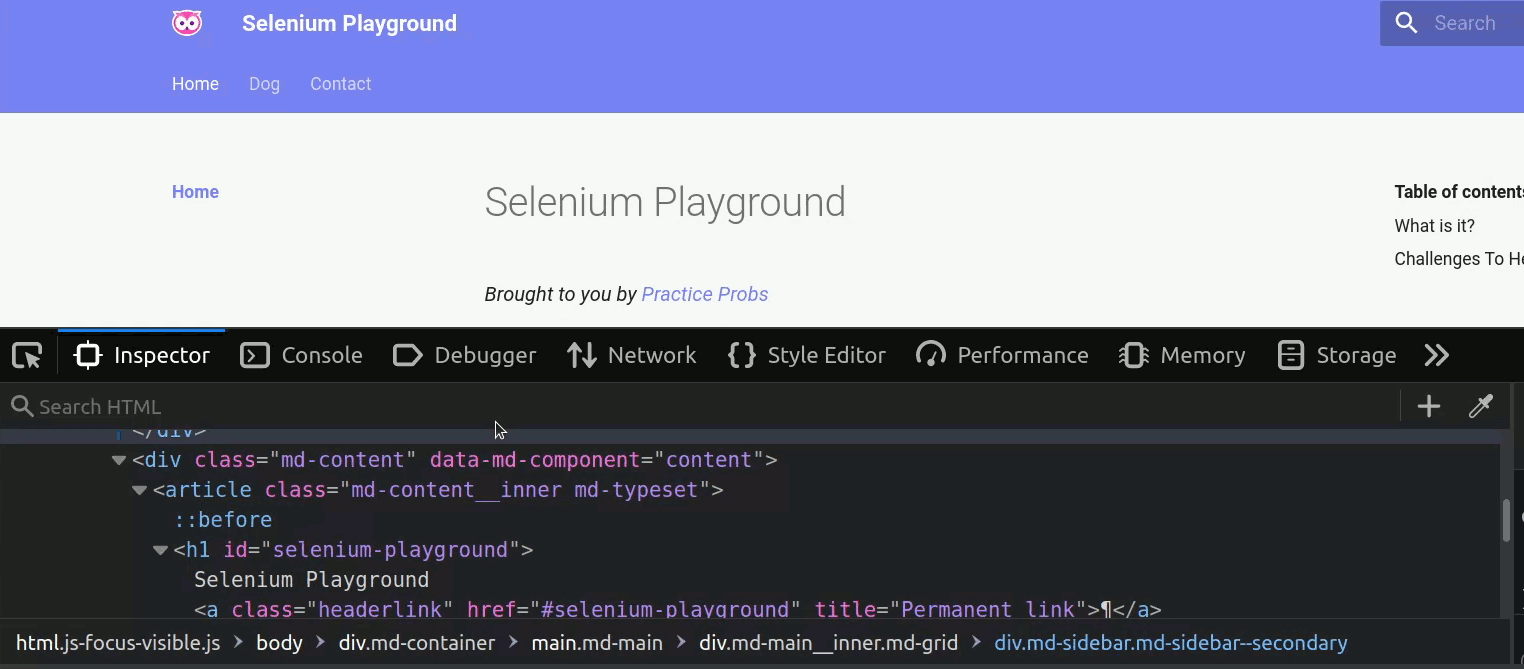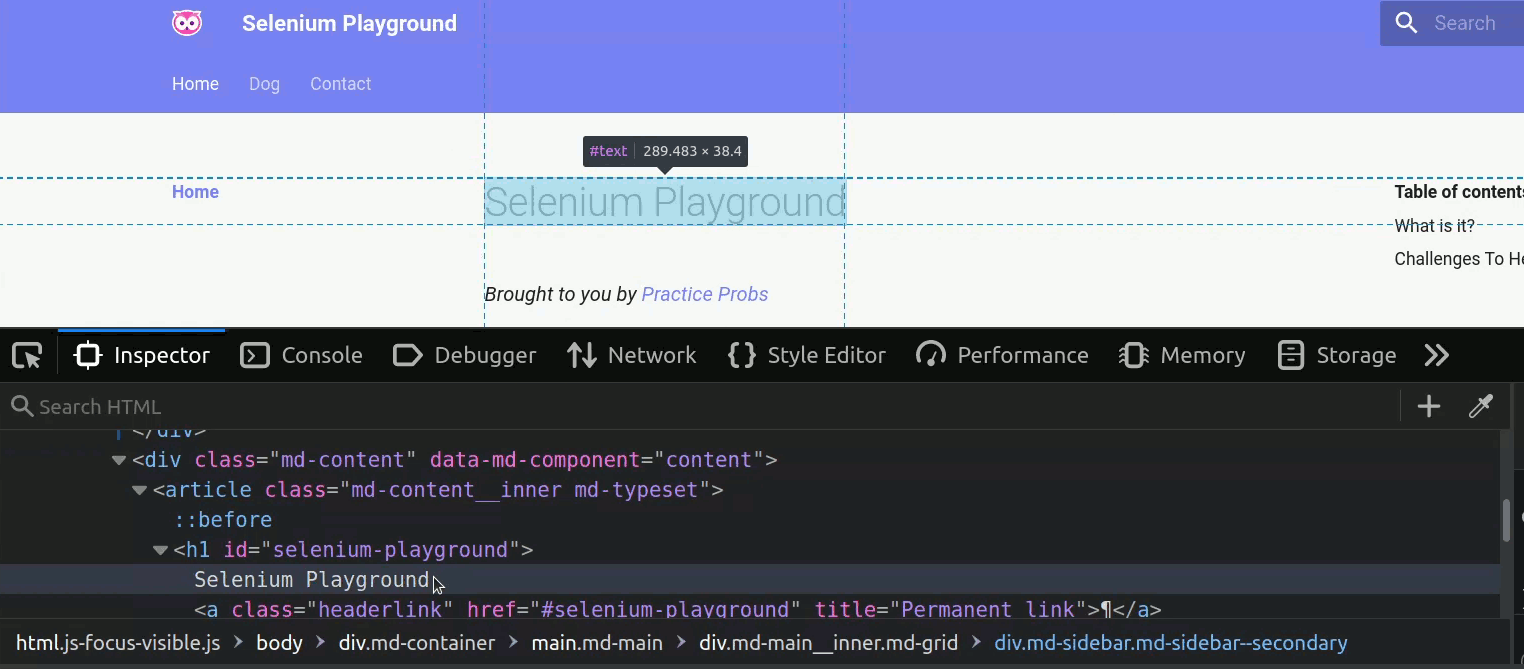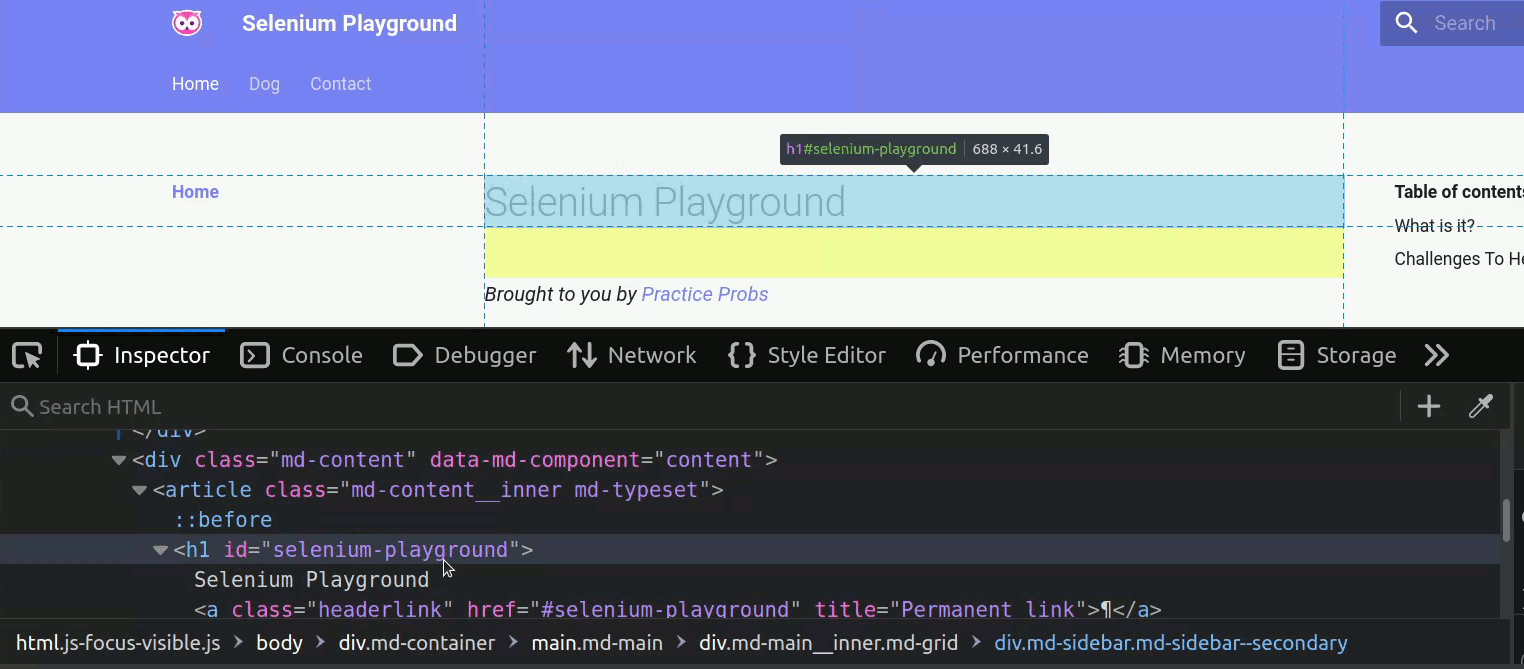
We can see that the element we are looking for is an h1 element with the property id="selenium-playground".
Hence, we can select it using the WebDriver.find_element() method.
title = driver.find_element(By.ID, "selenium-playground")
type(title) # (1)!
<class 'selenium.webdriver.remote.webelement.WebElement'>
titleis a WebElement.
Next, we retrieve the inner HTML using the WebElement.get_attribute() method.
html = title.get_attribute("innerHTML")
type(html)
# <class 'str'>
print(html)
# Selenium Playground<a class="headerlink" href="#selenium-playground" title="Permanent link">¶</a>
By simply splitting the string at each < character, we can isolate the actual title from the <a/> element
behind it.
html.split("<")
# ['Selenium Playground', 'a class="headerlink" href="#selenium-playground" title="Permanent link">¶', '/a>']
title_str = html.split("<")[0]
print(title_str)
# Selenium Playground
Thereby, we are able to extract the title of the page as a string using Selenium! 
Don't forget to close the web driver!
driver.close()
You should close the web driver as soon as you're done using it. Doing so frees up memory and compute resources for your machine.
Feel free to play around with this a little, and try to extract different text elements from the home page. How about a secondary header or some paragraph text?